Academic reproducibility#
This notebook is a tutorial on how to make our code reproducible. Starting from downloading pyJedAI, data and then creating a pipeline to run the code.
pyJedAI has been tested upon almost all the famous datasets used for benchmarking in ER area. More specifically, pyJedAI has been tested on the following datasets:
\(D_{1}\): Contains restaurant descriptions, first used in OAEI 2010.
\(D_{2}\): Encompasses duplicate products from the online retailers Abt.com and Buy.com Köpcke et al., 2010.
\(D_{3}\): Matches product descriptions from Amazon.com and the Google Base data API (GB) Köpcke et al., 2010.
\(D_{4}\): Entails bibliographic data from DBLP and ACM Köpcke et al., 2010.
\(D_{5}\), \(D_{6}\), \(D_{7}\): Involve descriptions of television shows from TheTVDB.com (TVDB) and movies from IMDb and themoviedb.org (TMDb) Obraczka et al., 2021.
\(D_{8}\): Matches product descriptions from Walmart and Amazon Mudgal et al., 2018.
\(D_{9}\): Involves bibliographic data from publications in DBLP and Google Scholar (GS) Köpcke et al., 2010.
\(D_{10}\): Interlinks movie descriptions from IMDb and DBpedia, including a different snapshot of IMDb than \(D_{5}\) and \(D_{6}\) Papadakis et al., 2020.
\(D_{11}\): A dataset with characteristics substantially different from the others — unlike the limited size and schema of the other datasets, it contains millions of heterogeneous entities with user-generated content, using 50,000 different attributes from two versions of DBpedia that differ chronologically by 3 years Papadakis et al., 2020.
Dataset Specifications#
Test |
Dataset Specs |
#D1 |
#D2 |
#Duplicates |
|---|---|---|---|---|
D1 |
Restaurants1-Restaurants2 |
340 |
2257 |
89 |
D2 |
Abt-Buy |
1077 |
1076 |
1076 |
D3 |
Amazon-Google Products |
1355 |
3040 |
1103 |
D4 |
DBLP-ACM |
2617 |
2295 |
2225 |
D5 |
IMDB-TMDB |
5119 |
6057 |
1969 |
D6 |
IMDB-TVDB |
5119 |
7811 |
1073 |
D7 |
TMDB-TVDB |
6057 |
7811 |
1096 |
D8 |
Walmart-Amazon |
2555 |
22075 |
853 |
D9 |
DBLP-Google Scholar |
2517 |
61354 |
2309 |
D10 |
IMDB-DBPedia |
27616 |
23183 |
22864 |
All the datasets are available in the Zotero repository.
📖 Don’t forget to cite us!
If you find this work useful, please cite us using the following reference:
@inproceedings{pyJedAI,
author = {Nikoletos, Konstantinos and Papadakis, George and Koubarakis, Manolis},
booktitle = {Demo at International Semantic Web Conference.},
series = {ISWC},
title = {{pyJedAI: a lightsaber for Link Discovery}},
year = {2022}
}
Thank you! 🌟
Download datasets#
Download the datasets from the Zenodo repository. After download extract the datasets.
!curl -L -o ccer_data.tar.gz "https://zenodo.org/records/13946189/files/ccer_data.tar.gz?download=1"
!tar -xf ccer_data.tar.gz
How to install pyJedAI?#
pyJedAI is an open-source library that can be installed from PyPI.
For more: pypi.org/project/pyjedai/
Dataset: Abt-Buy dataset (D1)
The Abt-Buy dataset for entity resolution derives from the online retailers Abt.com and Buy.com. The dataset contains 1076 entities from abt.com and 1076 entities from buy.com as well as a gold standard (perfect mapping) with 1076 matching record pairs between the two data sources. The common attributes between the two data sources are: product name, product description and product price.
!pip install pyjedai -U
!pip show pyjedai
Imports
import os
import sys
import pandas as pd
import networkx
from networkx import draw, Graph
import pyjedai
Data Reading using an easy-to-use method#
pyJedAI in order to perfrom needs only the tranformation of the initial data into a pandas DataFrame. Hence, pyJedAI can function in every structured or semi-structured data. In this case Abt-Buy dataset is provided as .csv files.
from pyjedai.utils import read_data_from_json
data = read_data_from_json(json_path='./data/configs/D2.json',
base_dir='./data/',
verbose=True)
***************************************************************************************************************************
Data Report
***************************************************************************************************************************
Type of Entity Resolution: Clean-Clean
Dataset 1 (abt):
Number of entities: 1076
Number of NaN values: 0
Memory usage [KB]: 563.56
Attributes:
name
description
price
Dataset 2 (buy):
Number of entities: 1076
Number of NaN values: 0
Memory usage [KB]: 336.63
Attributes:
name
description
price
Total number of entities: 2152
Number of matching pairs in ground-truth: 1076
───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Hint: If you want to benchmark all of them, just add a for loop and iterate over the datasets.
data.dataset_1.head(5)
| id | name | description | price | |
|---|---|---|---|---|
| 0 | 0 | Sony Turntable - PSLX350H | Sony Turntable - PSLX350H/ Belt Drive System/ ... | |
| 1 | 1 | Bose Acoustimass 5 Series III Speaker System -... | Bose Acoustimass 5 Series III Speaker System -... | 399 |
| 2 | 2 | Sony Switcher - SBV40S | Sony Switcher - SBV40S/ Eliminates Disconnecti... | 49 |
| 3 | 3 | Sony 5 Disc CD Player - CDPCE375 | Sony 5 Disc CD Player- CDPCE375/ 5 Disc Change... | |
| 4 | 4 | Bose 27028 161 Bookshelf Pair Speakers In Whit... | Bose 161 Bookshelf Speakers In White - 161WH/ ... | 158 |
data.dataset_2.head(5)
| id | name | description | price | |
|---|---|---|---|---|
| 0 | 0 | Linksys EtherFast EZXS88W Ethernet Switch - EZ... | Linksys EtherFast 8-Port 10/100 Switch (New/Wo... | |
| 1 | 1 | Linksys EtherFast EZXS55W Ethernet Switch | 5 x 10/100Base-TX LAN | |
| 2 | 2 | Netgear ProSafe FS105 Ethernet Switch - FS105NA | NETGEAR FS105 Prosafe 5 Port 10/100 Desktop Sw... | |
| 3 | 3 | Belkin Pro Series High Integrity VGA/SVGA Moni... | 1 x HD-15 - 1 x HD-15 - 10ft - Beige | |
| 4 | 4 | Netgear ProSafe JFS516 Ethernet Switch | Netgear ProSafe 16 Port 10/100 Rackmount Switc... |
data.ground_truth.head(3)
| D1 | D2 | |
|---|---|---|
| 0 | 206 | 216 |
| 1 | 60 | 46 |
| 2 | 182 | 160 |
Creating a custom pyJedAI pipeline using the ER datasets#
Block Building#
It clusters entities into overlapping blocks in a lazy manner that relies on unsupervised blocking keys: every token in an attribute value forms a key. Blocks are then extracted, possibly using a transformation, based on its equality or on its similarity with other keys.
The following methods are currently supported:
Standard/Token Blocking
Sorted Neighborhood
Extended Sorted Neighborhood
Q-Grams Blocking
Extended Q-Grams Blocking
Suffix Arrays Blocking
Extended Suffix Arrays Blocking
from pyjedai.block_building import (
StandardBlocking,
QGramsBlocking,
ExtendedQGramsBlocking,
SuffixArraysBlocking,
ExtendedSuffixArraysBlocking,
)
/home/conda/miniconda3/envs/pyjedai_env/lib/python3.9/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
bb = StandardBlocking()
blocks = bb.build_blocks(data, attributes_1=['name'], attributes_2=['name'])
Standard Blocking: 100%|██████████| 2152/2152 [00:00<00:00, 61937.01it/s]
bb.report()
Method name: Standard Blocking
Method info: Creates one block for every token in the attribute values of at least two entities.
Parameters: Parameter-Free method
Attributes from D1:
name
Attributes from D2:
name
Runtime: 0.0362 seconds
_ = bb.evaluate(blocks, with_classification_report=True)
***************************************************************************************************************************
Method: Standard Blocking
***************************************************************************************************************************
Method name: Standard Blocking
Parameters:
Runtime: 0.0362 seconds
───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Performance:
Precision: 0.45%
Recall: 99.54%
F1-score: 0.90%
───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Classification report:
True positives: 1071
False positives: 236447
True negatives: 1156695
False negatives: 5
Total comparisons: 237518
───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Block Purging#
Optional step
Discards the blocks exceeding a certain number of comparisons.
from pyjedai.block_cleaning import BlockPurging
bp = BlockPurging()
cleaned_blocks = bp.process(blocks, data, tqdm_disable=False)
Block Purging: 100%|██████████| 2934/2934 [00:00<00:00, 621111.79it/s]
bp.report()
Method name: Block Purging
Method info: Discards the blocks exceeding a certain number of comparisons.
Parameters:
Smoothing factor: 1.025
Max Comparisons per Block: 3224.0
Runtime: 0.0061 seconds
_ = bp.evaluate(cleaned_blocks)
***************************************************************************************************************************
Method: Block Purging
***************************************************************************************************************************
Method name: Block Purging
Parameters:
Smoothing factor: 1.025
Max Comparisons per Block: 3224.0
Runtime: 0.0061 seconds
───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Performance:
Precision: 1.12%
Recall: 98.61%
F1-score: 2.21%
───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Block Cleaning#
Optional step
Its goal is to clean a set of overlapping blocks from unnecessary comparisons, which can be either redundant (i.e., repeated comparisons that have already been executed in a previously examined block) or superfluous (i.e., comparisons that involve non-matching entities). Its methods operate on the coarse level of individual blocks or entities.
from pyjedai.block_cleaning import BlockFiltering
bf = BlockFiltering(ratio=0.8)
filtered_blocks = bf.process(cleaned_blocks, data, tqdm_disable=False)
Block Filtering: 100%|██████████| 3/3 [00:00<00:00, 40.00it/s]
bf.evaluate(filtered_blocks)
***************************************************************************************************************************
Method: Block Filtering
***************************************************************************************************************************
Method name: Block Filtering
Parameters:
Ratio: 0.8
Runtime: 0.0762 seconds
───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Performance:
Precision: 2.56%
Recall: 96.10%
F1-score: 4.99%
───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
{'Precision %': 2.562450436161776,
'Recall %': 96.09665427509294,
'F1 %': 4.991792990248141,
'True Positives': 1034,
'False Positives': 39318,
'True Negatives': 1156658,
'False Negatives': 42}
Comparison Cleaning - Meta Blocking#
Optional step
Similar to Block Cleaning, this step aims to clean a set of blocks from both redundant and superfluous comparisons. Unlike Block Cleaning, its methods operate on the finer granularity of individual comparisons.
The following methods are currently supported:
Comparison Propagation
Cardinality Edge Pruning (CEP)
Cardinality Node Pruning (CNP)
Weighed Edge Pruning (WEP)
Weighed Node Pruning (WNP)
Reciprocal Cardinality Node Pruning (ReCNP)
Reciprocal Weighed Node Pruning (ReWNP)
BLAST
Most of these methods are Meta-blocking techniques. All methods are optional, but competive, in the sense that only one of them can part of an ER workflow. For more details on the functionality of these methods, see here. They can be combined with one of the following weighting schemes:
Aggregate Reciprocal Comparisons Scheme (ARCS)
Common Blocks Scheme (CBS)
Enhanced Common Blocks Scheme (ECBS)
Jaccard Scheme (JS)
Enhanced Jaccard Scheme (EJS)
from pyjedai.comparison_cleaning import (
WeightedEdgePruning,
WeightedNodePruning,
CardinalityEdgePruning,
CardinalityNodePruning,
BLAST,
ReciprocalCardinalityNodePruning,
ReciprocalWeightedNodePruning,
ComparisonPropagation
)
mb = WeightedEdgePruning(weighting_scheme='EJS')
candidate_pairs_blocks = mb.process(filtered_blocks, data, tqdm_disable=True)
_ = mb.evaluate(candidate_pairs_blocks)
***************************************************************************************************************************
Method: Weighted Edge Pruning
***************************************************************************************************************************
Method name: Weighted Edge Pruning
Parameters:
Node centric: False
Weighting scheme: EJS
Runtime: 0.1479 seconds
───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Performance:
Precision: 10.86%
Recall: 91.45%
F1-score: 19.41%
───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Want to export pairs in this step?#
Every step provides a method named export_to_df that exports all pairs in dataframe. If you wish to export them in a file use .to_csv from pandas.
pairs_df=mb.export_to_df(candidate_pairs_blocks)
pairs_df.head(5)
| id1 | id2 | |
|---|---|---|
| 0 | 0 | 205 |
| 1 | 0 | 193 |
| 2 | 0 | 53 |
| 3 | 0 | 55 |
| 4 | 0 | 697 |
Entity Matching#
It compares pairs of entity profiles, associating every pair with a similarity in [0,1]. Its output comprises the similarity graph, i.e., an undirected, weighted graph where the nodes correspond to entities and the edges connect pairs of compared entities.
from pyjedai.matching import EntityMatching
em = EntityMatching(
metric='cosine',
tokenizer='char_tokenizer',
vectorizer='tfidf',
qgram=3,
similarity_threshold=0.0
)
pairs_graph = em.predict(candidate_pairs_blocks, data, tqdm_disable=True)
draw(pairs_graph)

_ = em.evaluate(pairs_graph)
***************************************************************************************************************************
Method: Entity Matching
***************************************************************************************************************************
Method name: Entity Matching
Parameters:
Metric: cosine
Attributes: None
Similarity threshold: 0.0
Tokenizer: char_tokenizer
Vectorizer: tfidf
Qgrams: 3
Runtime: 0.3382 seconds
───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Performance:
Precision: 10.86%
Recall: 91.45%
F1-score: 19.41%
───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
How to set a valid similarity threshold?#
Configure similariy threshold with a Grid-Search or with an Optuna search. Also pyJedAI provides some visualizations on the distributions of the scores.
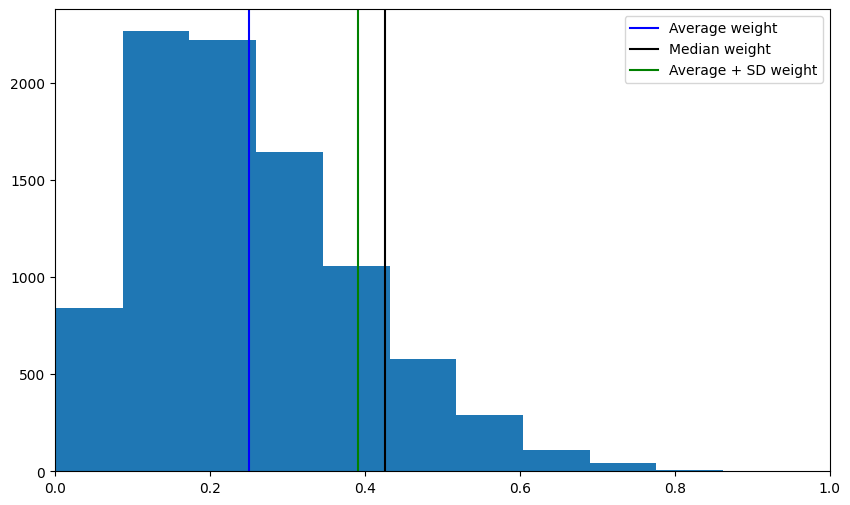
For example with a classic histogram:
em.plot_distribution_of_all_weights()
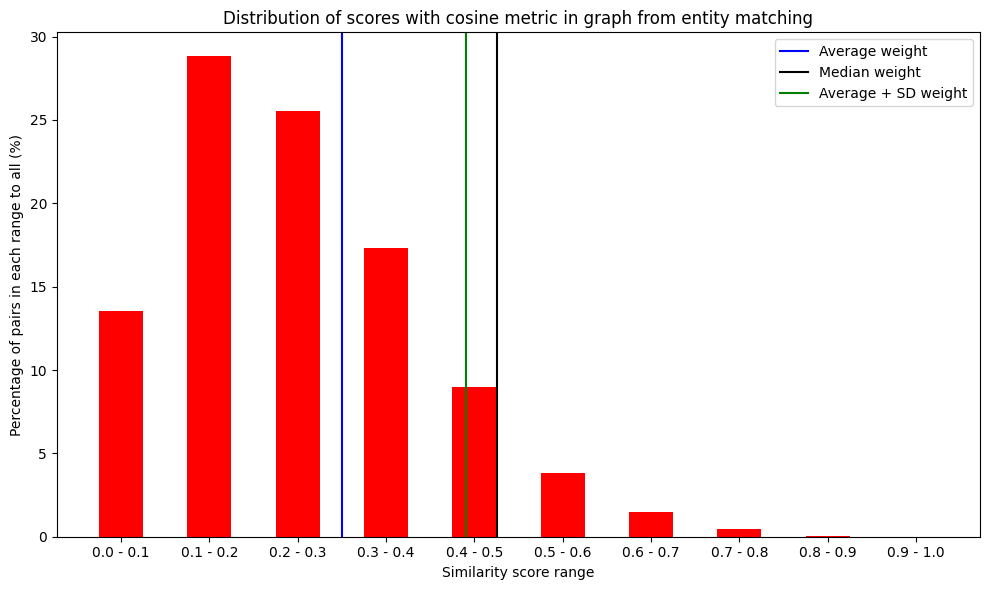
Or with a range 0.1 from 0.0 to 1.0 grouping:
em.plot_distribution_of_scores()
Distribution-% of predicted scores: [13.551092474067536, 28.8126241447804, 25.5131317589936, 17.325093798278527, 9.00463473846833, 3.8402118737585518, 1.4566320900463474, 0.4634738468329287, 0.03310527477378062, 0.0]
Entity Clustering#
It takes as input the similarity graph produced by Entity Matching and partitions it into a set of equivalence clusters, with every cluster corresponding to a distinct real-world object.
from pyjedai.clustering import ConnectedComponentsClustering, UniqueMappingClustering
ccc = UniqueMappingClustering()
clusters = ccc.process(pairs_graph, data, similarity_threshold=0.17)
ccc.report()
Method name: Unique Mapping Clustering
Method info: Prunes all edges with a weight lower than t, sorts the remaining ones indecreasing weight/similarity and iteratively forms a partition forthe top-weighted pair as long as none of its entities has alreadybeen matched to some other.
Parameters:
Similarity Threshold: 0.17
Runtime: 0.0284 seconds
_ = ccc.evaluate(clusters)
***************************************************************************************************************************
Method: Unique Mapping Clustering
***************************************************************************************************************************
Method name: Unique Mapping Clustering
Parameters:
Similarity Threshold: 0.17
Runtime: 0.0284 seconds
───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Performance:
Precision: 92.69%
Recall: 86.06%
F1-score: 89.25%
───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────